




What is Machine Learning?
AI is an extremely general term that is inclusive of several fields such as machine learning (ML), natural language processing (NLP), expert systems and many more. In this article, we will discuss one of the most popular fields in AI: machine learning.
In a nutshell, ML is a subset of AI that is used to determine trends with given data. This can be used to make predictions or classifications. In this and following articles, we will go into the specific processes that allow a box of silicon to make logical inferences and predictions using data.
Supervised Learning
At its core, ML has two components: supervised machine learning and unsupervised machine learning.
Suppose we wanted to predict the monthly income of a person based on his/her age. To do this task, we will need to first find some data. After this is done, the data needs to be organized into a DataFrame.
A DataFrame is a tabular form of the raw data provided to us. So, in our scenario, the DataFrame will look something like this:
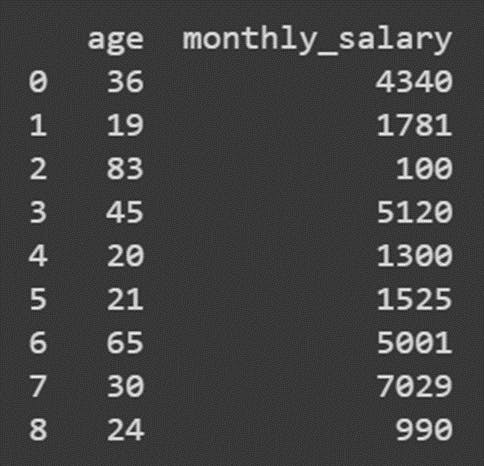
Imagine a black box that can receive an input and can produce an output. The output is affected by what we feed as the input into the system. This DataFrame is similar to such an abstraction. Age is the input parameter while monthly salary is the output. Formally, we call the input parameter a feature and the output value a target.
So, basically, when we provide the age (that is called a feature) to our machine learning model, a prediction about the monthly salary (that is called a target) is made. There are numerous steps that go in between. However, in this article, I hope to provide a basic overview about the system. As we move forward, I will go into the inner workings of supervised learning.
The main takeaway from this section is that in supervised learning, we provide labelled data in the form of a DataFrame. We give an input (age of worker) and the corresponding output (monthly income) to train our model.
Then, we ask our trained model to perform predictions based on new input values (new ages). The model should use its past experience with training data to make predictions (predict the monthly salary).
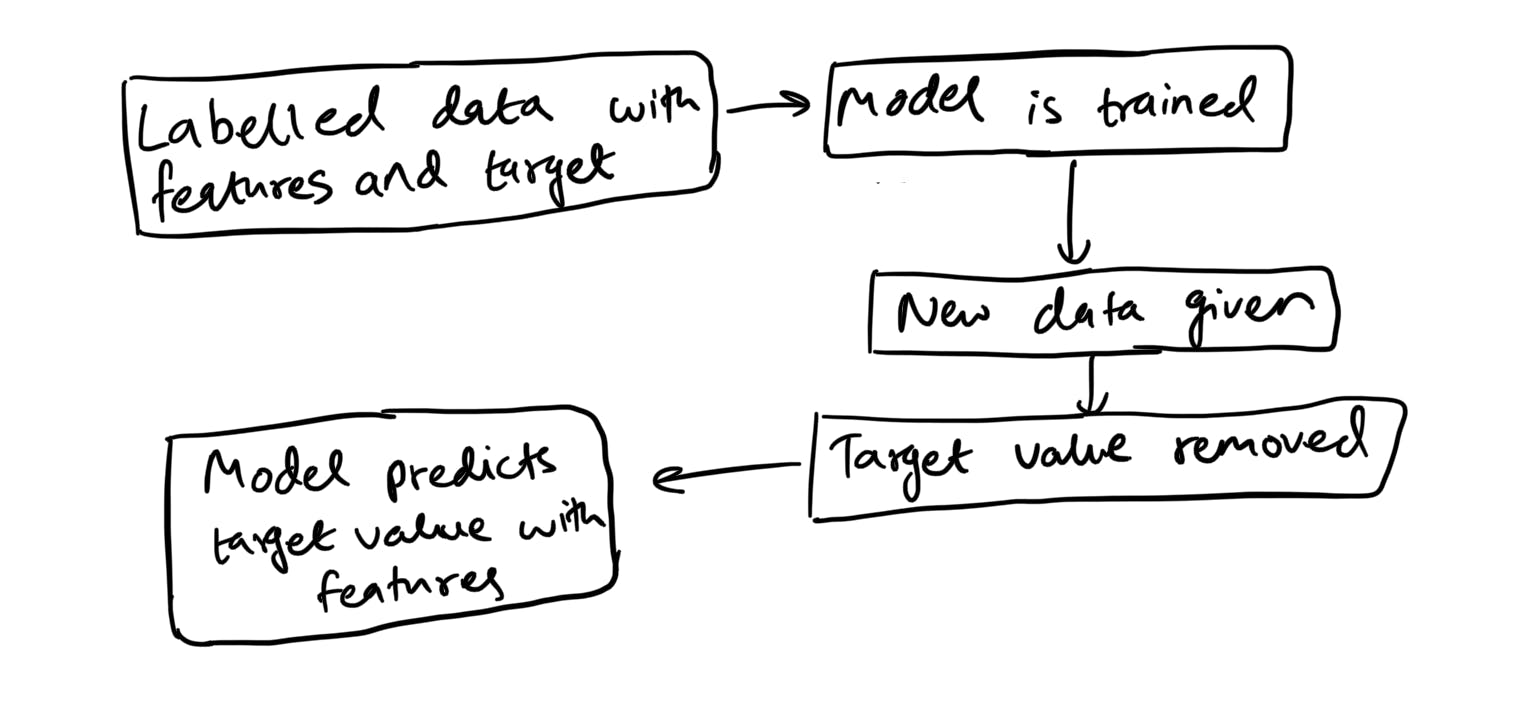
Data used to train our model is called training data. Data that is used when our model has to make predictions is called testing data. These two terms are extremely crucial in supervised learning.
Unsupervised learning
With supervised learning, we provided labelled data. We said that for a certain age, the person made a certain income. But with unsupervised learning, we do not provide a target value (the target value being the monthly income in our previous example). The machine makes predictions without any labelled data to train it.
Unsupervised learning is useful in several scenarios. Netflix predicts your choice of movies using unsupervised learning. Spotify determines your musical taste with unsupervised learning. The applications of this subset of machine learning are immense — particularly because we don't always have a target value.

In simple terms, unsupervised learning is a way for machines to learn without the presence of labelled data. It is effective in that as machines are exposed to more data, they begin to learn more and improve their predictive abilities — all by themselves!
Reinforcement learning
Reinforcement learning is the process of using rewards and penalties to make an AI system perform a particular task. Similar to how pets are given treats when they follow their master, the AI system is also rewarded when it does a task that helps it reach a goal.
Say we want to teach an AI system how to park a car. We need to assign the value zero to the reward variable. Then, when the AI system reaches closer to the parking spot we can reward it by increasing the value of the reward variable. In contrast, when the system hits another car, we can penalize it by reducing the value of the reward variable. The primary objective of the AI system, which is sometimes called an agent, is to maximize the value of the reward variable by doing certain actions we want it to do.
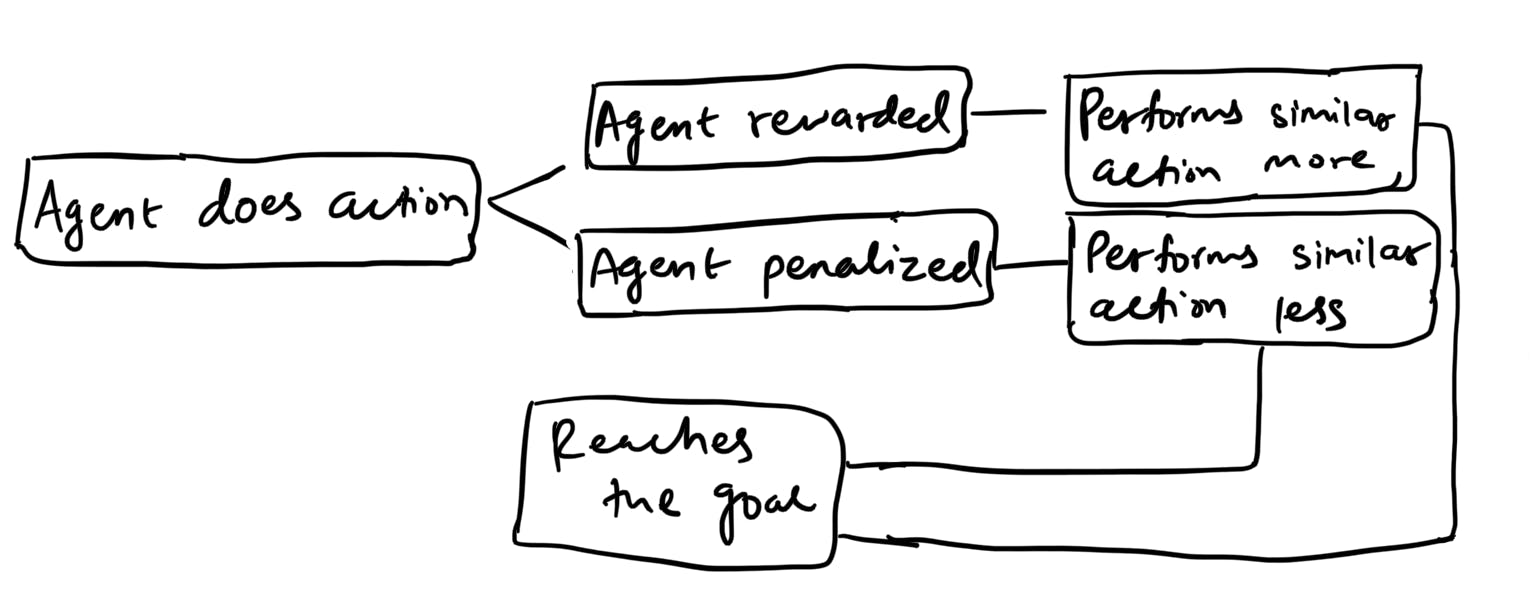
Two key aspects in this process are exploration and exploitation. In exploration, the agent would experiment and try to find the perfect way to park a car. During exploitation, however, the system will utilize its existing knowledge about parking to make decisions. A mix of both of these properties is essential for the agent to reach its goal.
Conclusion
I hope you have got a general idea about machine learning. In the coming few articles, I will go deeper into the functionalities of the learning methods we discussed. Subscribe to my newsletter to be notified when this series is updated. Thank you for reading and happy coding !
Image by iuriimotov on Freepik